BLAST是用来干什么的?
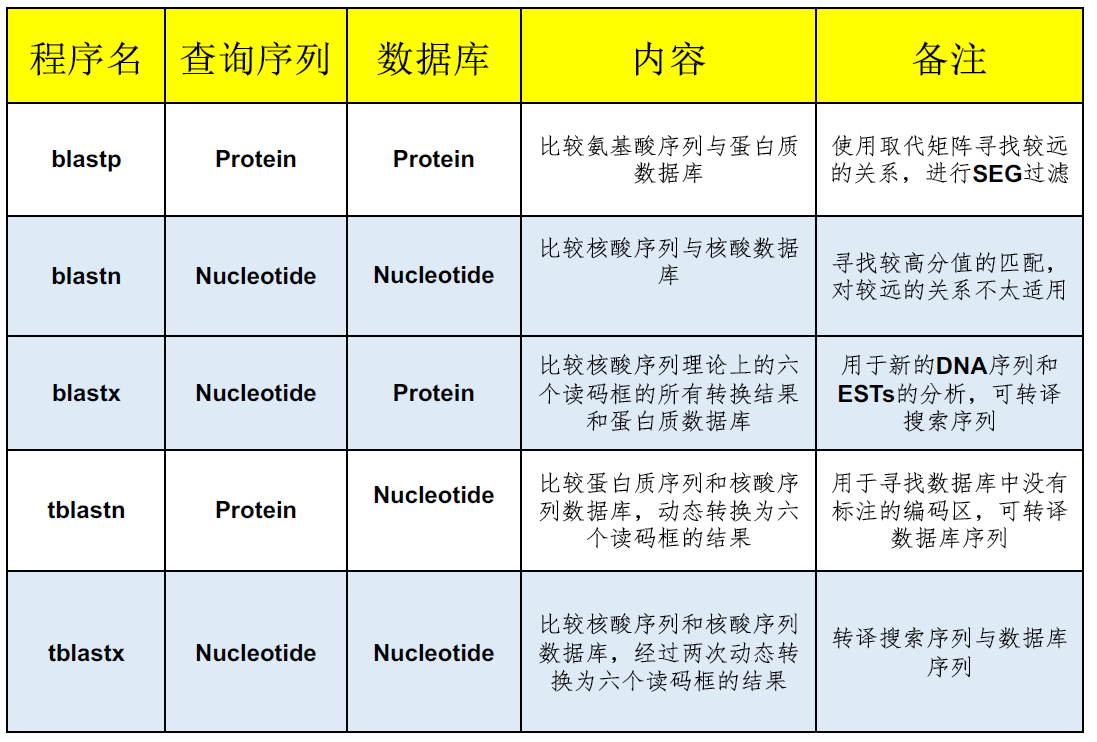
的有关信息介绍如下:BLAST包含五 个程序和若干个相应的数据库,分别针对不同的查询序列和要搜索的数据库类型。其中翻译的核酸库指搜索比对时会把核酸数据按密码子按所有可能的阅读框架转换成蛋白质序列。
BLAST对序列格式的要求是常见的FASTA格式。FASTA 格式第一行是描述行,第一个字符必须是“>”字符;随后的行是序列本身,一般每行序列不要超过80个字符,回车符不会影响程序对序列连续性的看法。 序列由标准的IUB/IUPAC氨基酸和核酸代码代表;小写字符会全部转换成大写;单个“-”号代表不明长度的空位;在氨基酸序列里允许出现“U”和 “*”号;任何数字都应该被去掉或换成字母(如,不明核酸用“N”,不明氨基酸用 “X”)。此外,对于核酸序列,除了A、C、G、T、U分别代表各种核酸之外,R代表G或A(嘌呤);Y代表T或C(嘧啶);K代表G或T(带酮基);M 代表A或C(带氨基);S代表G或C(强);W代表A或T(弱);B代表G、T或C;D代表G、A或T;H代表A、C或T;V代表G、C或A;N代表A、 G、C、T中任意一种。对于氨基酸序列,除了20种常见氨基酸的标准单字符标识之外,B代表Asp或Asn;U代表硒代半胱氨酸;Z代表Glu或Gln; X代表任意氨基酸;“*”代表翻译结束标志。
BLASTp:用蛋白质序列搜索蛋白质序列库
BLASTn:用核酸序列搜索核酸库
BLASTx:核酸序列对蛋白质库的比对,核酸序列在比对之前自动按照六个读码框翻译成蛋白质序列
tBLASTn:蛋白质序列对核酸库的比对,核酸库中的序列按照六个读码框翻译后与蛋白质序列进行比对搜索
tBLASTx:核酸序列对核酸库在蛋白质质级别的比对,两者都在搜索之前翻译成为蛋白质质进行比对