什么是声纹识别?
的有关信息介绍如下:语音携带的信息非常丰富,大家普遍了解的语音识别是指对语音内容的识别技术,即解决了“给定语音到底说了什么”的问题。
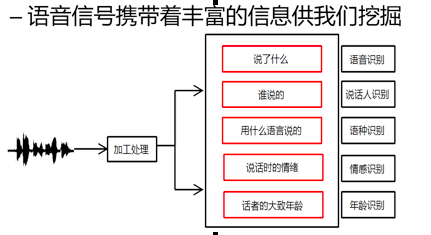
声纹识别简单的说就是判断给定的一句话到底是谁说的技术。早在上世纪40年代末期就有相关研究者开始进行相关技术的探索,主要应用于军事情报领域。其理论基础就是“每个人的说话特性都具有其独特的特征”,而决定这种独特特征的主要因素有:
1、声腔的差异,其包括咽喉、鼻腔、口腔以及胸腔等,这些欺诳的形状、尺寸和位置决定了声腔的差异。因此大家可以感受到,不同的人说话,其声音的频率分布是不同的;
2、发声的操作方式,主要是指唇、口齿、舌头等部位在发声时的相互作用。
一般而言,人在逐渐的学习过程中就会慢慢的形成了自己的声纹特性,正常说话时的声纹状态还是相对稳定的。但是声纹特性仍然具有易变性,因为影响声纹特性的两个因素非常容易受身体状况、年龄、情绪等情况的干扰,从而导致声纹特性的变化。例如:人随着年龄的变化声纹特性也在随之变化,尤其是小时候和成年后;人在感冒时由于鼻腔堵塞等问题会明显感觉到声纹特性的不一致等。当然,人也可以通过刻意的模仿等形成不同的声纹特性。总而言之,声纹特征是类似于虹膜、指纹等一种具有独特性的生物特征。
声纹识别从任务上来说,主要分为声纹确认技术(1:1)和声纹识别技术(1:N)两类。声纹确认技术回答的是两句话到底是不是一个人说的问题,而声纹识别技术回答的则是”给定的一句话属于样本库中谁说的”问题。


